Hybrid Neural Networks for On-device Directional Hearing
Anran Wang* Maruchi Kim* Hao Zhang Shyam Gollakota
University of Washington
36th AAAI Conference on Artificial Intelligence (2022)
Abstract
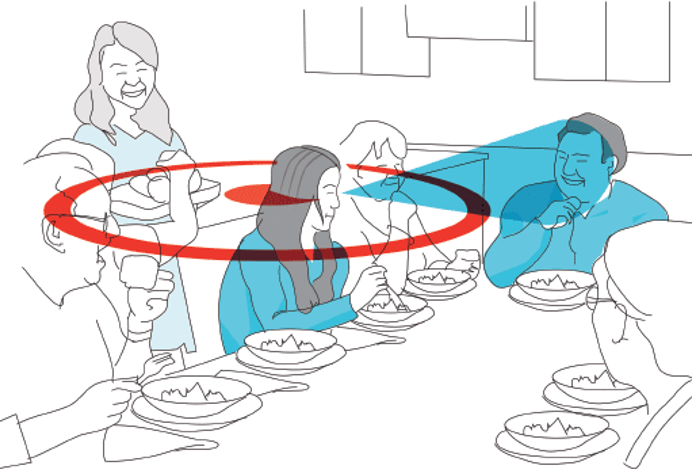
On-device directional hearing requires audio source separation from a given direction while achieving stringent human-imperceptible latency requirements. While neural networks can achieve significantly better performance than traditional beamformers, all existing models fall short of supporting low-latency causal inference on computationally-constrained wearables.
We present DeepBeam, a hybrid model that combines traditional beamformers with a custom lightweight neural network. The former reduces the computational burden of the latter and also improves its generalizability, while the latter is designed to further reduce the memory and computational overhead to enable real-time and low-latency operations. Our evaluation shows comparable performance to state-of-the-art causal inference models on synthetic data while achieving a 5x reduction of model size, 4x reduction of computation per second, 5x reduction in processing time and generalizing better to real hardware data. Further, our real-time hybrid model runs in 8 ms on mobile CPUs designed for low-power wearable devices and achieves an end-to-end latency of 17.5 ms.
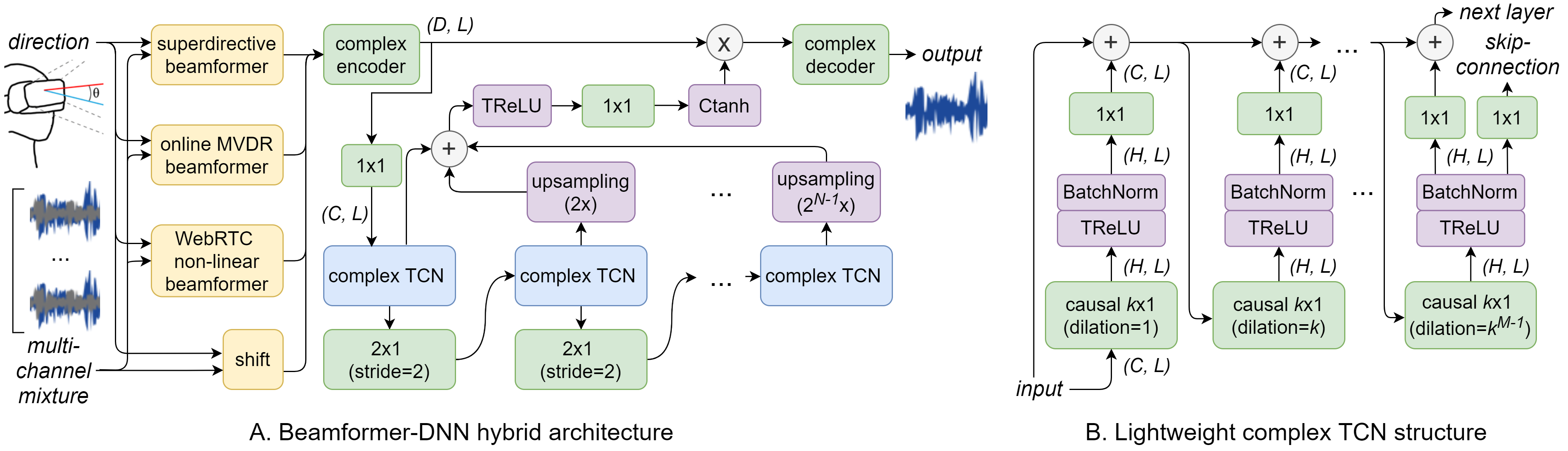
Our model consists of a series of complex-valued, causal, strided and dilated convolutional networks which drastically reduces the computational overhead and memory footprint while maintaining a low latency.
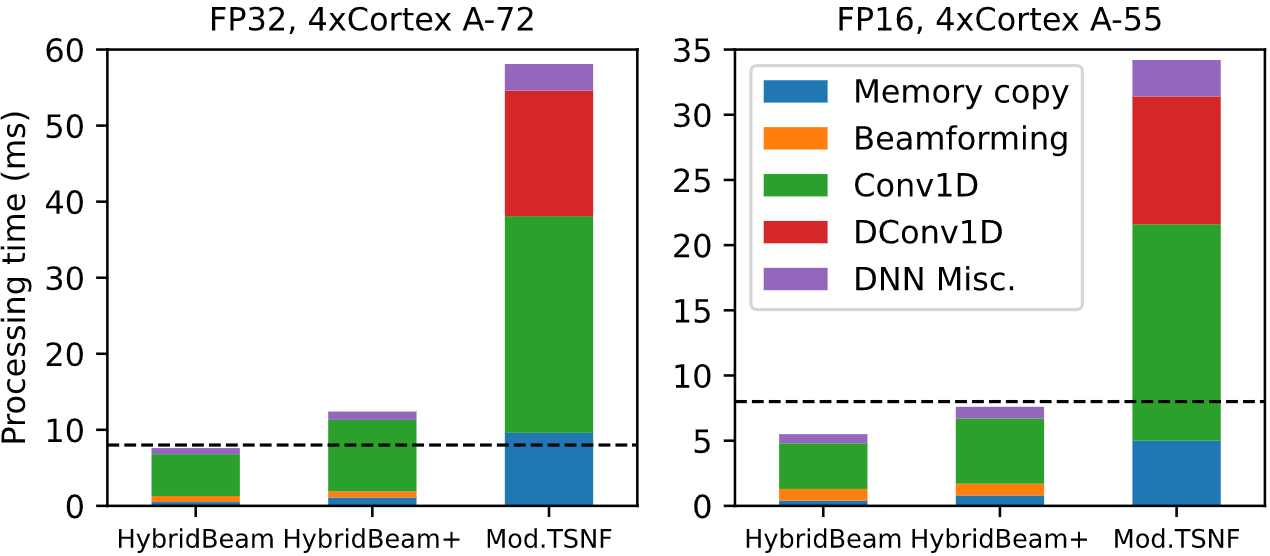
We achieve real-time directional hearing with a 17.5ms end-to-end latency on two different embedded platforms, 5x better than the prior state-of-the-art [1,2].
Comparisons
We show comparisons with groundtruth on a challenging synthetic audio mixture using a virtual 6-mic array, and also comparisons with existing state-of-the-art models on real recorded data using a Seeed 6-mic array [3].
Performance using synthetic audio mixtures:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Mixture | Groundtruth | Our result |
|---|
Real-world recording samples using a 6-mic array
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Mixture | Ours | TSNF [1] |
|---|
[1] Gu, R.; and Zou, Y. 2020. Temporal-spatial neural filter: Direction informed end-to-end multi-channel target speech separation. arXiv preprint arXiv:2001.00391
[2] Luo, Y.; Han, C.; Mesgarani, N.; Ceolini, E.; and Liu, S.-C. 2019. Fasnet: Low-latency adaptive beamforming for multi-microphone audio processing. In 2019 IEEE ASRU Workshop, 260–267. IEEE
[3] https://www.seeedstudio.com/ReSpeaker-6-Mic-Circular-Array-Kit-for-Raspberry-Pi.html
Source code
[Code]Citation
Acknowledgements
We thank Les Atlas, Steve Seitz, Laura Trutoiu and Ludwig Schmidt for their important feedback on this work.